A look at the performance of expression templates in C++: Eigen vs Blaze vs Fastor vs Armadillo vs XTensor
It is March 2020. C++20 is almost around the corner and as a scientific C++ programmer I am quite thrilled with the new features that the language is getting. Of these features quite a few of them are designed to help us with our day-to-day numerical computing in C++. These include ranges-v3, views andspan, in particular. Perhaps what most of us have always desired to have in C++ are finally making it to the language, things like construction and indexing of multi-dimensional arrays in a way that is familiar to scientific programmers, lazy and on-demand evalutation of operations and broadcasting a scalar operation over an entire range. These are the kind of things that you would typically get from a dedicated C++ scientific package or what people typically refer to as expression template libraries. In line with the theme of this article I will consider the three new features coming to C++ before we start having a look at these scientific packages themselves. First, let us consider the std::span which is in essence a non-owning view over any piece of contiguous memory
std::vector<double> vec = {1,2,3,4,5,6,7,8};
auto s = std::span<double, 3>(vec.begin(),3);// index s now as
auto isTrue = s[1] == 2;
But what is more interesting is std::mdspan which allows you to view your data as a multi-dimensional array
auto ms = std::mdspan<double, 2, 2, 2>(vec.begin(), vec.end());// index ms now as
auto isTrue = ms(1,0,0) == 5;
and just like that we have created a fixed-size row-major 3-dimensional array of size2x2x2and we are already indexing it in the same way as we do in MATLAB. Certainly dynamic views are also possible using dynamic_extents. std::mdspanprimarily solves the problem of block-indexing and slicing.
Consider the issue of on-demand evaluation and broadcasting now using views. Applying a function (or a lambda) to a whole range is now possible using views
std::vector<int> values = {0,1,2,3,4,5};
auto square = [](int i) { return i * i; };
for (int i : values | std::views::transform(square)) {
std::cout << i << ' ';
}This will apply the lambda function square to every element of the vector values and generate the elements one-by-one, i.e. lazily. So we are sorted with broadcasting and lazy evaluation too.
The last piece and what most scientific programmers are also typically concerned with is efficiency and performance of their code. Well, aside from basic threading withstd::threadwe now also have std::execution::parfor parallel execution of many of the numeric algorithms. We now also have explicit SIMD vectorisation with std::experimental::simd with proper intrinsic vector and mask types. So say on an AVX512 enabled architecture you can compute the dot product of two vectors in one go like
using abi = std::experimental::simd_abi::avx512;
using V = std::experimental::simd<T,abi>;std::vector<double> a = {1,2,3,4,5,6,7,8};
std::vector<double> b = {10,20,30,40,50,60,70,80};double dotted = (V(a)*V(b)).sum();
Putting all these pieces together, it seems like we have all of what other technical languages and domain specific packages offer built in the language. Well, we have always had all of them, it is just that syntactically we are much closer while still being in the bare-metal performance zone of C++.
So where does this leave the state of numerical computing in C++. I believe while the aforementioned features are fundamental for the future of scientific computing in C++, their adoption in the technical community will take time and it is less likely that computational scientists will code in such a C++-esque style with say range based generators, explicit simd types and so on given that computational scientists are not programming language enthusiasts. Computational scientists want mathematical syntax, dirt simple APIs, free functions and interactive feedback. Hence, comes the need for domain specific libraries that put these features together in an easy and efficient way.
So it is about time to have another look at the state of scientific computing libraries available today in C++ and see where they are in this respect. I reckon one of the reasons that Python has become the numerical language of choice is because of the power of NumPy. Despite it’s flaws what has made NumPy so central to numerical computing is it’s broadcasting and slicing of multi-dimensional arrays and it’s universal functions capabilities. Fortunately, today we have a few numerical libraries in C++ as well that come quite close to NumPy’s syntax. Most of these C++ numerical linear algebra packages are built on one promise — abstract away low-level implementation and provide a nearly mathematical syntax for the user without sacrificing on performance. In particular, what all these libraries really excel at is “lazy” or “delayed” evaluation of operations with not so flexible broadcasting and slicing capabilities.
So let us do a little experiment with some of these libraries and test some of these features (delayed evaluation when multiple operations are chained, array views and broadcasting) and have a look at their interfaces and see if one performs better than the other or compiles faster than the other. We will choose the following libraries (all latest branches from github/gitlab/bitbucket)
- Eigen
- Blaze
- Fastor
- Armadillo
- XTensor
Eigen has almost become an industry-standard scientific computing package, albeit it deals primarily with matrices (2D tensors). XTensor is a rather new but very promising library that is hoping to become the NumPy of C++ in the coming future and even more by providing bindings back to Python, Julia and R. Armadillo has been around for quite a while and in fact predates C++11 (I believe) which provides quite a similar syntax to MATLAB. Blaze is another C++ library much like Eigen but promises to deliver higher performance. Fastor is yet another new C++ library for on-the-stack multi-dimensional tensor algebra that attempts to implement numerical linear algebra using the Einstein index notation. Aside from XTensor and Fastor none of the other aforementioned libraries provide generic multi-dimensional array/tensor support. Certainly, Eigen has it is unsupported but rather mature tensor package as well. Although, I have to say that amongst these Fastor is a pretty niche library in that it only deals with stack-allocated tensors in order to perform sophisticated mathematical optimisations at compile-time for tensor products/contractions etc. It certainly isn’t trying to be another Eigen.
Our experiment is a simple fourth-order finite difference scheme for the Laplace equation on a Cartesian grid that has been benchmarked elsewhere on the internet for other languages/packages in the past. The beauty of this problem is that it really tests the performance of array views, delayed evaluation and slicing/broadcasting when there is aliasing. In NumPy, the code looks something like this:
u[1:-1, 1:-1] = ((u[0:-2, 1:-1] + u[2: , 1:-1] +
u[1:-1, 0:-2] + u[1:-1, 2:]) * 4.0 +
u[0:-2, 0:-2] + u[0:-2, 2:] +
u[2: , 0:-2] + u[2: , 2:]) / 20.0where “u” is a square matrix of size [num*num where num=100,150,200]. At least to help with aliasing we are going to make an explicit copy. Written in Fastor (and in fact Eigen 3.4 as well which will be released sometime this year) this code will look something like this:
Change “Tensor” to “Eigen::Matrix<double,num,num>” and you get an Eigen implementation (not exactly as sequences in Eigen are closed sets — they include the ends). If you change seq to span you will get the Armadillo implementation. In XTensor the code looks something like this:
which is slightly different than Eigen, Fastor and Armadillo. That is theview is applied as a free function on the array rather than the array being indexed with a range. Blaze also has a similar design to XTensor where aview is called a submatrix. While the choice is subjective, Eigen’s, Fastor ‘s and Armadillo’s syntax certainly look more familiar to NumPy/MATLAB users than XTensor’s and Blaze’s syntax. Regardless, the bottom line is that with all these libraries we get pretty close to NumPy style slicing (although maybe a bit clunkier and we may need to do more typing than NumPy’s [start:end:step]).
Now let us assess the performance. For this performance benchmark, we will be hoping that all these packages will be able to fuse all the operations in to a single loop and generate an efficient SIMD code from it (one thing that we don’t normally get with vectorised NumPy code). We are also going to give the compiler all the flags it needs to do so. With GCC 9.2, I equip the compiler with the following flags knowing that expression templates are heavily dependent on the compilers ability to inline
-O3 -mavx2 -mfma -finline-limit=1000000 -ffp-contract=fastThe other nice thing about this benchmark is that it is iterative so the same function above is being called thousands of times, so in a way the problem at hand is a benchmark in itself. On top of that we will run each test 100 times and compute the mean timing. Here is the performance comparison between them with a grid of 200*200 and using double precision (all benchmarks are run on the 2018 macbook pro 13" — 2.3 GHz Quad-Core Intel Core i5 and the code for the benchmark repository is linked at the bottom of this article)
Package\Time | Time in seconds for N (num)=200
--------------|--------------------------------------------------
Eigen | 2.40657
--------------|--------------------------------------------------
Blaze | 2.37961
--------------|--------------------------------------------------
Fastor | 2.19099
--------------|--------------------------------------------------
Armadillo | 169.920
--------------|--------------------------------------------------
XTensor | 59.4571
--------------|--------------------------------------------------As you can see Eigen, Blaze and Fastor are pretty close in terms of speed. I would classify them as having the same performance. Looking at their assembly code we see that our finite difference function is turned in to this
We can observe that Eigen is marginally slower than Blaze [2%] which in turn is marginally slower than Fastor [8%], but that is mainly due to slight difference elsewhere in the generated code and not really in the main loop body. I would say, that this is as efficient as you would perhaps get. I have tested this benchmark in Fortran with Intel ifort’s most aggressive optimisation and have seen it emit a similar code although still around 10% slower than the above 3 libraries (around 3.0 seconds). Blaze by design turns division of a scalar with an expression (Expression / Number) in to multiplication (Expression * 1/Number). Fastor does not do this by default but can be asked to do so. The other two libraries Armadillo and XTensor are unfortunately not performing really well at this benchmark. Looking closer it seems like the bottleneck in their case is the norm function which requires a LAPACK call on the expression
norm(u - u_old) // armadillo
xt::linalg::norm(u - u_old) // xtensorI don’t know how Armadillo and XTensor deal with an expression that needs to be dispatched to BLAS/LAPACK. Do they evaluate the expression first? Even evaluating the result of “u — u_old” in to a temporary static matrix and then passing that to the norm function didn’t help speed up the code. Although there is no memory allocation here the cost of this evaluation is certainly blowing up the computational time.
In case of Eigen, Blaze and Fastor, since they have their own implementation the call to
norm(u - u_old)is fused in to a single fully unrolled AVX loop with further FMA instructions. Here is the full performance comparison for the three grid sizes [N=100, 150, 200] that I tested (values are time measurements in seconds so lower is better)
Package\Time | N=100 | N=150 | N=200
--------------|------------|------------|------------------------
Eigen | 0.13681 | 0.80114 | 2.40657
--------------|------------|------------|------------------------
Blaze | 0.13121 | 0.69373 | 2.37961
--------------|------------|------------|------------------------
Fastor | 0.11566 | 0.71270 | 2.19099
--------------|------------|------------|------------------------
Armadillo | 6.97169 | 37.7927 | 169.920
--------------|------------|------------|------------------------
XTensor | 3.95012 | 18.9261 | 59.4571
-----------------------------------------------------------------Note that Blaze also pads static matrices and explicitly unrolls loops that helps with small size matrices but hurts the performance when matrix size becomes bigger in this case. Unrolling more than the SIMD width typically only helps with cache-hot problems.
Although we have used the default machinary that these libraries provide without any hacks, I feel like the performance of Armadillo and XTensor is unacceptable. In fact it is worse than NumPy. So in the second attempt, let us write our own inline norm function (should not be recommended in general as the default functions that a library provides should give the best performance) for them:
Benchmarking again we get the following times:
Package\Time | N=100 | N=150 | N=200
--------------|------------|------------|------------------------
Eigen | 0.13681 | 0.80114 | 2.40657
--------------|------------|------------|------------------------
Blaze | 0.13121 | 0.69373 | 2.37961
--------------|------------|------------|------------------------
Fastor | 0.11566 | 0.71270 | 2.19099
--------------|------------|------------|------------------------
Armadillo | 0.43759 | 2.29904 | 6.52282
--------------|------------|------------|------------------------
XTensor | 0.73877 | 3.58291 | 11.1189
-----------------------------------------------------------------That helps a lot. The performance of the latter two libraries are now almost comparable to the rest with Eigen, Blaze and Fastor performing similarly and Armadillo being about 3 times slower and XTensor 5–6 times slower than them. I still feel like there is no reason for these libraries to perform slower. Looking even further at XTensor assembly code for instance, I can see that the call to
make_view_impland it’s callees further down are not inlined by the compiler. This is quite critical since operator chaining depends on it. If function are opaque to the compiler’s eye they wouldn’t be inlined and as a result the expression that is thus far chained will be evaluated one at a time which in essence would almost resemble the classic operator overloading (albeit in this case you would still be avoiding temporaries). Consequently, a single fused SIMD code cannot be generated.
So far so good. Let us turn to single precision floating point now. Computation with Float32 is quite common in GPU computing. I will run the same benchmark here with similar grid sizes but change the parameter type to Float32. I am hoping if these libraries truely emit SIMD code then I should get nearly 2X performance. Note that I will use my hacky norm function for Armadillo and XTensor again here. I will now provide the results in figures. For a grid of size of 100 I obtain the following results (lower is better):

Eigen and Fastor actually gain nearly 2X speed up going from double precision to single precision, with Fastor outperforming by a slight margin. Blaze is getting twice slower instead. Looking at it’s assembly code I see that at the risk of aggressively vectorising perhaps it is emitting a lot of conversion code
vcvtps2pd %xmm9, %ymm9a lot of it. If you look at the benchmark there is one multiplication and one division of the expressions with scalar values (which is kept as double precision — Float64). Both Eigen and Fastor cast the type of the scalar to the underlying scalar type of the expression while Blaze does not and in fact suffers from the conversion problem at runtime (unless the users casts their scalars explicitly). I would say, this type of type instability can easily go unnoticed if your design allows mixed precision arithmetics. As for the Armadillo and XTensor, given that the compiler cannot inline the whole expression, it is emiting the same seemingly scalar code so the performance remains almost identical to double precision. For a grid of size 150, I obtain the following results (lower is better):
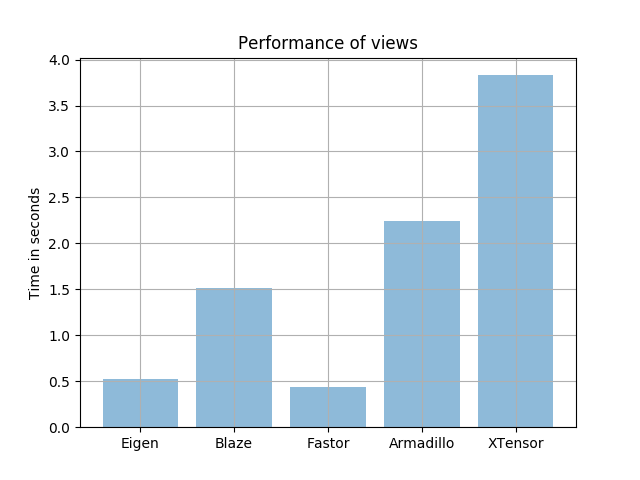
Similar story here. What I also noticed is given that the initial boundary condition to this finite difference problem is a trigonometric function with single precision different libraries give slightly different final norm values. This is to be expected when you do explicit SIMD I guess (timings are not affected by this).
So far we have looked at API design and performance. Let us now have a look at compilation times. Compiling the benchmark codes with the same flags I obtain (time — so lower is better):
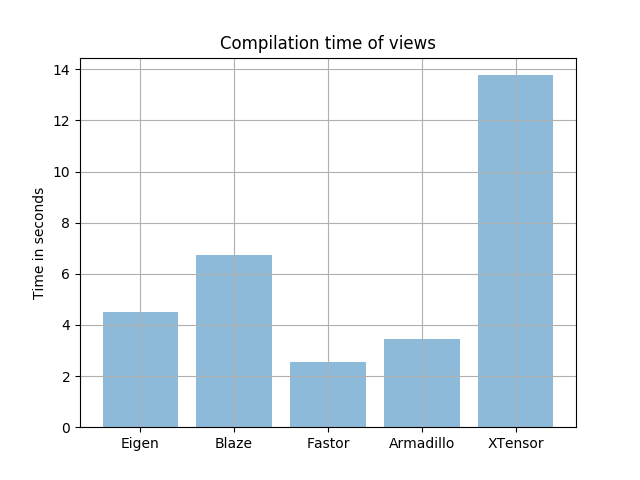
It turns out that XTensor is also quite heavy on the compiler with Blaze coming in second. Fastor compiles nearly 2 times faster than Eigen and 3–4 times faster than Blaze.
In conclusion, we can say that despite the fact that Eigen is typically compared to vendor BLAS in all benchmarks (where it may not perform equally well), Eigen provides the best balance in performance and compilation times for most numerical workload. It is certainly the case in this benchmark. No wonder it tops the list of all “Recommend me a C++ scientific library?” questions. Fastor is designed for fixed multi-dimensional arrays which is what this benchmark is about so certainly it shines here. Fastor also has lesser type-traits and call-indirections which helps it compile quicker. Blaze is certainly more tuned for performance and uses nefty techniques under the hood like padding, explicit loop-unrolling and turning divisions to multiplications to create more opportunities for FMA. However, aggressively tuning for performance implies more specialisations, more overloads, more “SFINAE” and so on and as result compiles slower than Eigen. Armadillo is perhaps the winner in compilation times if we exclude Fastor which is a smaller library. Solely going by the numbers in this benchmark it seems like XTensor is not quite as focussed on performance and compilation times at the moment (XTensor has not reached the stable 1.0 landmark yet), as providing NumPy style features/containers might be it’s top priority for the time being and I am quite hopeful that these numbers will change in it’s favour as it matures.
The full code for this benchmark can be found at: